Meta unveils Llama Guard 3: open-source AI safety filters
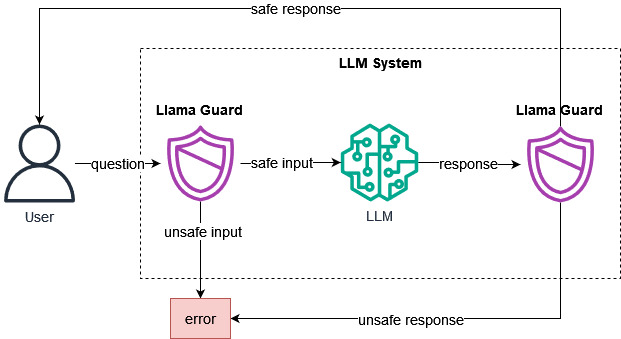
Meta has released Llama Guard 3, an open‑source safety and content moderation model designed to filter prompts and responses for generative AI systems, marking a significant step toward interoperable, auditable AI safety tooling[9]. According to Meta, the model introduces improved coverage for risky categories, multilingual support, and modular policies that can be adapted to different applications and jurisdictions[9]. Hugging Face and industry practitioners quickly highlighted its practical utility for both open‑weight and proprietary model deployments[10].
Why this matters
Safety filters are becoming a baseline requirement for deploying AI assistants in consumer and enterprise settings. By open‑sourcing Llama Guard 3 with clear policies and evaluation scripts, Meta provides a common layer teams can inspect, extend, and verify—addressing a frequent complaint about opaque, closed‑box safety systems[9]. Early community tests suggest it can replace brittle regex‑style filters with learned classifiers that generalize better to real‑world prompts[10].
What’s new in Llama Guard 3
- Expanded risk taxonomy and policy modularity: Meta outlines granular categories spanning self‑harm, hate, harassment, illegal activities, sexual content, and biosafety, with structured policies that map to allow/deny/transform actions developers can enforce in production[9].
- Multilingual coverage: The model is trained to handle multiple languages, a key need as generative AI usage globalizes beyond English‑first markets[9].
- Open evaluations and recipes: Meta ships evaluation datasets, reference pipelines, and guidance for integrating Guard into pre‑ and post‑generation filters, tool‑use gating, and system prompt hardening[9].
How it compares
- Against rule‑based filters: Community benchmarks show learned classifiers in Llama Guard 3 catching adversarial phrasings and obfuscated prompts that bypass regex/keyword lists, while reducing false positives on benign queries[10].
- Against closed systems: Unlike proprietary safety stacks, Guard’s policies and weights are auditable, enabling compliance teams to trace coverage and customize thresholds for regulated domains[9].
Implementation and impact
- Plug‑and‑play in the stack: Developers can place Llama Guard 3 before model calls (prompt screening) and after (output screening), and use it to gate tool calls (e.g., web browsing, code execution) based on risk labels[9].
- Enterprise readiness: The release targets real‑world needs like policy versioning, multilingual moderation queues, and logging for audits—features enterprises cite as blockers to production AI rollouts[9].
- Ecosystem uptake: Hugging Face Spaces and example repos surfaced within hours, with practitioners sharing prompt suites that stress‑test jailbreaks and LLM‑to‑LLM attacks, accelerating hardening cycles[10].
What experts are watching next
Researchers and trust‑and‑safety teams are evaluating Llama Guard 3’s robustness under adversarial testing, domain transfer to specialized agents, and alignment with emerging international AI governance rules. Meta indicates that continued community feedback will shape policy granularity and model iterations, signaling an ongoing cadence of open safety releases[9].
Outlook
Open, auditable safety layers are becoming foundational infrastructure for AI deployments. If Llama Guard 3’s early performance holds up under red‑teaming and multilingual stress tests, it could become a de facto standard for baseline safety filtering across open and closed models, lowering integration costs and improving transparency industry‑wide[9][10].
How Communities View Llama Guard 3
The debate centers on whether open‑sourcing safety filters meaningfully improves real‑world AI safety or simply offers marginal gains over closed systems.
-
Pragmatic adopters (~40%): Builders praise the modular policy design and quick integration into pre/post filters, sharing code snippets and early metrics on reduced jailbreak rates. Examples: @jules_ai notes smooth gating of tool calls; r/LocalLLaMA threads swap prompt‑attack suites and report fewer false positives on benign dev queries[10].
-
Transparency advocates (~25%): Policy and governance voices welcome auditable weights and evaluable policies, arguing this supports compliance and external audits. @policytensor highlights value for regulated sectors and cross‑border deployments, citing traceability as the key win[9].
-
Skeptics/red‑teamers (~20%): Security researchers claim determined jailbreaks still succeed and caution against overreliance on a single guard model. r/MachineLearning commenters post adversarial examples; @adversarially argues for ensemble guards and behavior‑level sandboxes.
-
Ecosystem integrators (~15%): Infra engineers at AI startups celebrate immediate availability on Hugging Face and simple wrappers for LangChain/LlamaIndex. @hf_engineering threads show Spaces with evaluation harnesses and shared leaderboards[10].
Overall sentiment: cautiously positive. Practitioners see Llama Guard 3 as a practical, auditable baseline that’s better than regex stacks, while researchers push for layered defenses and continuous red‑teaming[9][10].